cat - This multitool can help you more than you think
When you think about essential Linux command-line tools, cat is probably one of the first that comes into mind. Short for “concatenate”, this seemingly simple command is part of the basic equipment of every Linux user’s toolkit. Most commonly, it’s used to display the contents of a file in the terminal - a quick and easy way to peek inside a document.
But if you think that’s all cat is good for - you’re in for a surprise :-)
cathas a few tricks up its sleeve, that can help you to streamline your workflow: From transforming data to merging files or creating new ones -catdefinitively deserves a closer look.
And along the way, I promise, we will stumble upon one or the other interesting tool or concept too …
Let’s start simple and understand the basic way cat is working
If you start cat on the command line without any additional parameter, then you will “lose your prompt”: You’ll have only a cursor on a blank line as a sign that you can enter some text:
Now if you enter some text and finish your input-line by hitting “<enter>”, then cat will immediately repeat the line you just typed in:

After that - again an empty line with a lonely cursor. Now you can enter the next line, which will also be repeated and so on. (you can stop the cat command in this state at any time by simply hitting <ctrl>+c)
what we just observed is exactly the way how cat works:
- It reads in data line by line from its input datastream, which is by default bound to the terminal - and therefore to your keyboard.
- The output of
catthen goes to its output datastream, that is in this simple example bound to the terminal.
For illustration: This is part of a screenshot taken from the video I linked below: On the left-hand side I’ve tried to draw a keyboard, on the right-hand side a terminal (such an artist I am … :))

If you prefer watching instead of reading, here is the video covering the essentials from this post:
Useful command-line switches for “cat”
Now, that we have used cat in this simple manner, let’s try out some useful command-line switches.
First let’s start with numbering lines …
With an added -n at the command line, cat numbers all the lines it prints out:
[robert@demo ~]$ cat -n
let's type in a line
1 let's type in a line
and now a second one
2 and now a second one
finally a third
3 finally a third
^C
[robert@demo ~]$
again - just hit <ctrl>+c to end cat.
Obviously this isn’t a really useful way to use cat. But how about numbering the lines of a file for better readability or for making references? If you add the name of a file to the command line, then cat uses this file for its input instead of your keyboard:
[robert@demo ~]$ cat -n test.txt
1 this is a simple file for testing
2 the content means nothing
3
4 really nothing
5
And yes - if you omit the -n parameter from the example above, cat just prints out the content of the file without further modifications. This I the way I bet you have used this tool myriads of times before …
Although cat knows a second parameter for tweaking the numbering (-b only counts non-empty-lines):
if you need a ninja-tool for numbering text-data, have a look at nl which let’s you do the numbering in every possible way I may think of.
In its most basic variant, nl works just like cat -n without numbering completely empty lines:
[robert@demo ~]$ nl test.txt
1 this is a simple file for testing
2 the content means nothing
3
4 really nothing
(Do you see the seemingly empty line numbered with “3”? Read further to see with cat why this line is numbered.)
BTW: If you need to persist the output of a command for later usage or investigation, send the output of the command to a file by just appending > filename to the command line:
cat -n test.txt > test_cat_numbered.txt
or
nl test.txt > test_nl_numbered.txt
This works with every command line you use:
To save the output of a command into a file, append
> a_filenameto the end of the command just like inls -l /etc > list.txt.
Back to the seemingly empty numbered line from the example above …
Use cat to detect special characters
If you use cat to print out the content of a file, then you always only see a representation of the data, done by the terminal.
If you see an empty line, then this line doesn’t necessarily have to be really empty: It may, for instance, contain several white spaces or TABs.
To make these typically invisible characters visible, cat can help you with a few parameters:
Use -E to see the end of each line.
With the parameter -E, cat prints at the very end of each line a ‘$’-sign as a visual marker:
[robert@demo ~]$ cat -E test.txt
this is a simple file for testing$
the content means nothing $
$
really nothing$
$
As you can see, the third line isn’t completely empty as it seemed first: The $-sign as the line-end-marker is indented like the lines above and below.
To see, if the line is indented by spaces or by tabs, the next parameter is helpful …
Use -t so see markers for TABs
Tabulators will be visually marked with ^I , if you use the -t parameter:
[robert@demo ~]$ cat -t test.txt
this is a simple file for testing
^Ithe content means nothing
really nothing
[robert@demo ~]$
As you can see, the only line here containing a TAB is the first one. The other indented lines are indented with spaces.
And of course, you can use parameters in combination for showing TABs and line-endings at once:
[robert@demo ~]$ cat -tE test.txt
this is a simple file for testing$
^Ithe content means nothing $
$
really nothing$
$
[robert@demo ~]$
… where cat -tE ... is just the shorthand form for writing cat -t -E ...
See all other non-printing characters with -v
While -E and -t are for marking line-endings and TABs, the -v parameter is for all the other non-printing characters, that could be embedded in the file.
What’s the thing with “non-printing” characters? Well ..
Think about reading a text-file that was generated on a Windows system:
While a line-break on a Linux system (or any other Unix-like system like macOS) consists of only one single character (the “Line Feed” - represented as “\n”), Windows-systems use two characters instead: a “Carrige Return” followed by a “Line Feed” (represented as “\r\n”).
If you process such files with the tools you know, you may see odd and unusual results.
To see the additional “Carrige Return” characters in a file, call cat -v ... as in the following example:
[robert@demo ~]$ cat -v test_win.txt
this is a simple file for testing^M
the content means nothing ^M
^M
really nothing^M
^M
[robert@demo ~]$
The ^M markers you see at the end of each line represent the added “Carrige Return” characters. (btw: all non-printing characters shown with -v will be marked as ^M)
side-note: If you want to convert line-endings between Windows- and Linux-style, you can use dos2unix or unix2dos if available on your system. If they are not, have a look at tr or sed respectively to do the modifications.
To convert a text file from Window line-endings to Unix line-endings, you can use one of the following commands to remove the unwanted “Carrige Return” characters (“\r”):
sed 's/\r//' text_win.txt > text_unix.txtortr -d '\r' < text_win.txt > text_unix.txt
See them all at once with -A
With -A, you can combine the functionality of -E ,-t and -v into one single parameter. That’s how I typically make it easy for myself if I want to know if there are - somwehere in a file or a datastream - special characters that could create problems while further processing the data.
For instance, if grep or sed don’t work as I expect them to, I often ask cat to show me invisible characters I may not be aware of:
cat -A a_filename
Or, if I have the plan to further process the output of a command and I need to know if this command uses TABs or spaces for separation, I simply pipe the output of this command to cat -A.
As an example, try the following on one of your systems:
df -h | cat -A
This gives you via df -h the fill level of all your mounted filesystems as a table, and cat -A will show you, how this table is built.
Concatenate files, and how to split one first
Beside marking special characters, cat is a helpful tool to combine data - text or binary - into one single file.
Let’s pretend you have a really huuuuge file like this:

Yes - I know - this isn’t this huge. You have seen larger files than this one, but for the purpose of this demo, this works perfectly.
So let’s pretend, we have a file that is too large to handle it the way we want: If I want to sent this file via email, I need to take care of the maximal attachment size my email provider dictates.
Or imagine, we have the image of a large virtual machine or a backup-archive we want to transfer somewhere else.
Then it can be helpful to split the larger file into smaller parts, handle or transfer these parts, and concatenate them at the end.
How to split a large file into parts with split
To split a file into parts, you can use split -b <size> <filname>, where <size> is a number followed by an optional unit like “10M” or “100K”. Without a unit, the number is interpreted as the a number of bytes.
I want to split my file “demolog” file into chunks not larger than 100MB. If I do this with split, the created file-parts will by default be named “xa”, “xb”, “xc” and so on:

As you can see, my 357MB large file was split into three files with 100MB each and one that holds the remaining 57MB.
To get more convenient filenames for the single parts, you can add a filename-prefix as a last parameter in the following way:

Now I have my perfectly named file-parts, which I can process as desired.
But in the end, I want to restore my file from theses single parts. And this is where cat comes into play again:
How to concatenate files with ‘cat’
We can use the feature here, that cat can print out multiple files at once - one after the other:
cat file1 file2 file3 ...
And it doesn’t matter if these files are simple textfiles or binaries - cat just prints them out without adding one single byte itself to the output data.
And if we combine this with redirecting the output of the command into a single file, we can really simple concatenate multiple files to a single one:
cat demolog_aa demolog_ab demolog_ac demolog_ad > demolog_new
We can even simplify this a lot, if we use a filename pattern (demolog_*) instead of typing in every single filename on our own.
This works perfectly here, because the shell will build a list of filenames from the given pattern, ordered alphabetically. And this is exactly what we need.
Concatenate all files matching “demolog_*” to one single new file called “demolog2”:
Prove that the new file holds the same content as the original
As a last step, we need to verify that the concatenated file holds exactly the same data as the original:

Both files have exactly the same size - a good starting point. But is there really every single byte still in its place? Let’s verify this by calculating a checksum for both files:

Since the calculated checksums match exactly, we have proven that splitting and then concatenating the file again was completely lossless.
If you want to check, if two files hold exactly the same content or not, you can calculate a checksum for each file and compare them. Common tools are
md5sumfor calculating an MD5-checksum orsha1sumfor calculating a checksum based on SHA1.
shameless plug by the author: If you want to learn more about tools like the ones we talk about here, check out the “ShellToolBox”. You can find it at shelltoolbox.com or on Amazon.
Create new files with cat
There are many ways for creating new files at the command line. From using the simple touch command like
touch new_filename
to using output-redirection with an empty command like this:
> new_filename
Both versions have one thing in common - they give you an empty new file.
But sometimes you want to load initial content into the newly created file.
For this you can use cat with the following pattern:
[robert@demo ~]$ cat << END > new_file
the content goes here
you could even paste text data
from the clipboard
END
The pattern << END is called the “HERE-operator”, where the phrase “END” is a phrase you chose on your own.
The shell then starts the command line and collects everything you type in until the phrase you placed after the << is seen standalone on a single line.
The collected data is then given to the input datastream of the command.
And as you now know, cat reads in everything from its input datastream and prints it out again.
This output is the redirected via > new_file into a newly created file.
Let’s prove the functionality:
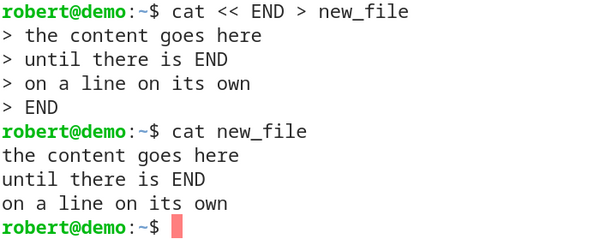
that worked.
Here is what to do next

If you followed me through this article, you certainly have realized that knowing some internals about how things are working at the Linux command line, can save you a lot of time and frustration.
And sometimes it’s just fun to leverage these powerful mechanics.
If you wanna know more about such “internal mechanisms” of the Linux command line - written especially for Linux beginners
have a look at “The Linux Confidence Framework”
In this framework I guide you through 5 simple steps to feel comfortable at the Linux command line.
This framework comes as a free pdf and you can get it here.
Wanna take an unfair advantage?

If it comes to working on the Linux command line - at the end of the day it is always about knowing the right tool for the right task.
And it is about knowing the tools that are most certainly available on the Linux system you are currently on.
To give you all the tools for your day-to-day work at the Linux command line, I have created “The ShellToolbox”.
This book gives you everything
- from the very basic commands, through
- everything you need for working with files and filesystems,
- managing processes,
- managing users and permissions, through
- software management,
- hardware analyses and
- simple shell-scripting to the tools you need for
- doing simple “networking stuff”.
Everything in one single, easy to read book. With explanations and example calls for illustration.
If you are interested, go to shelltoolbox.com and have a look (as long as it is available).


